
Partha Chakraborty
I build retrieval and ranking systems that work at scale. My work sits at the intersection of classical information retrieval and modern neural approaches: fine-tuning embedding models, designing hybrid search pipelines, and building the evaluation infrastructure that tells you whether search is actually getting better.
At Coalition Inc., I work on enterprise search and knowledge retrieval: a production hybrid search system combining dense vector and text indexes across tens of thousands of sources, a fine-tuned bi-encoder for semantic entity resolution, and an evaluation platform covering both classical search metrics and LLM-based quality signals. Before that, I fine-tuned vision-language models at Huawei Canada and built a learning-to-rank system for ad retrieval across 21 Amazon marketplaces.
My research at the University of Waterloo explored the same problem space from the academic side. RLocator applied reinforcement learning to learning-to-rank. BLAZE used hybrid retrieval with Reciprocal Rank Fusion for zero-shot code search. The embedding design work investigated what training strategies actually produce better bi-encoders. Adversarial techniques turned out to matter more than architecture choices.
Research Interests
Search & Ranking Systems Learning-to-rank, hybrid retrieval, dense and sparse signal fusion, and relevance evaluation. Interested in how classical IR techniques and neural approaches complement each other, and in evaluation frameworks that measure retrieval quality rigorously rather than by proxy metrics.
Representation Learning for Retrieval Embedding model training across bi-encoder and cross-encoder architectures, hard negative mining strategies, and domain adaptation. Particularly interested in cases where off-the-shelf embeddings fail and what it takes to fix them.
Production AI Systems LLM-based agents, RAG pipelines, multimodal models, and the evaluation and safety infrastructure that makes them trustworthy at scale. Search is often the retrieval backbone of these systems, but the system-level challenges go beyond retrieval quality alone.
Work Experience
Applied Scientist
April 2025 – Present
Enterprise Search and Retrieval at Scale
Built the search and knowledge retrieval infrastructure powering Coalition's enterprise AI platform. Core work includes a production hybrid search system combining Milvus dense vector indexes and text indexes across ~16K sources, a fine-tuned sentence transformer bi-encoder for semantic entity resolution trained with online hard negative mining, and a dual-layer evaluation platform tracking classical search metrics (MAP, MRR, nDCG, Hit@K) alongside LLM-based quality signals including faithfulness, completeness, and context relevance.
Also built an unsupervised intent discovery pipeline using embeddings, UMAP, and HDBSCAN to surface emerging user issues from unstructured conversations — moving beyond rigid predefined categories to identify real product gaps. The platform monitors 50+ agents and 30+ models with continuous evaluation runs every three hours, enabling regression detection and A/B testing across LLM providers.
Deep Learning Engineer
November 2024 – April 2025
Vision-Language Models for AI-Generated Content
Fine-tuned a vision-language model to generate photography composition instructions, achieving a 3% improvement in aesthetic classification accuracy over state-of-the-art. Improved model alignment through mixed preference optimization, increasing user acceptance by 10% in end-user evaluation. Reduced inference pipeline latency by 35% through dynamic quantization, enabling efficient large-scale deployment of the multimodal system.

Applied Scientist II Intern
September 2023 – December 2023
Learning-to-Rank for Ad Retrieval
Built a large-scale learning-to-rank model for ad retrieval across 21 Amazon marketplaces, improving ad-customer alignment by 3% through five novel engineered features and multi-objective ranking optimization. Designed ranking strategies that balanced competing signals across a high-traffic production advertising system.

Software Engineer
November 2018 – September 2020
Search, Personalization, and Platform Infrastructure
Built a personalized search system for address and point-of-interest retrieval, incorporating user attributes, history, and preferences into ranking. Achieved a 21.4% increase in CTR and a 5% reduction in search abandonment. Integrated intent-based ad placement into the search experience, generating $35K in revenue within two months of launch.
Also built a microservices-based streaming platform serving ~15K IoT devices using Redis and Elasticsearch, and a distributed data pipeline for validation and sanitization that reduced manual processing effort by 30%.

Projects
BLAZE: Hybrid Retrieval for Bug Localization
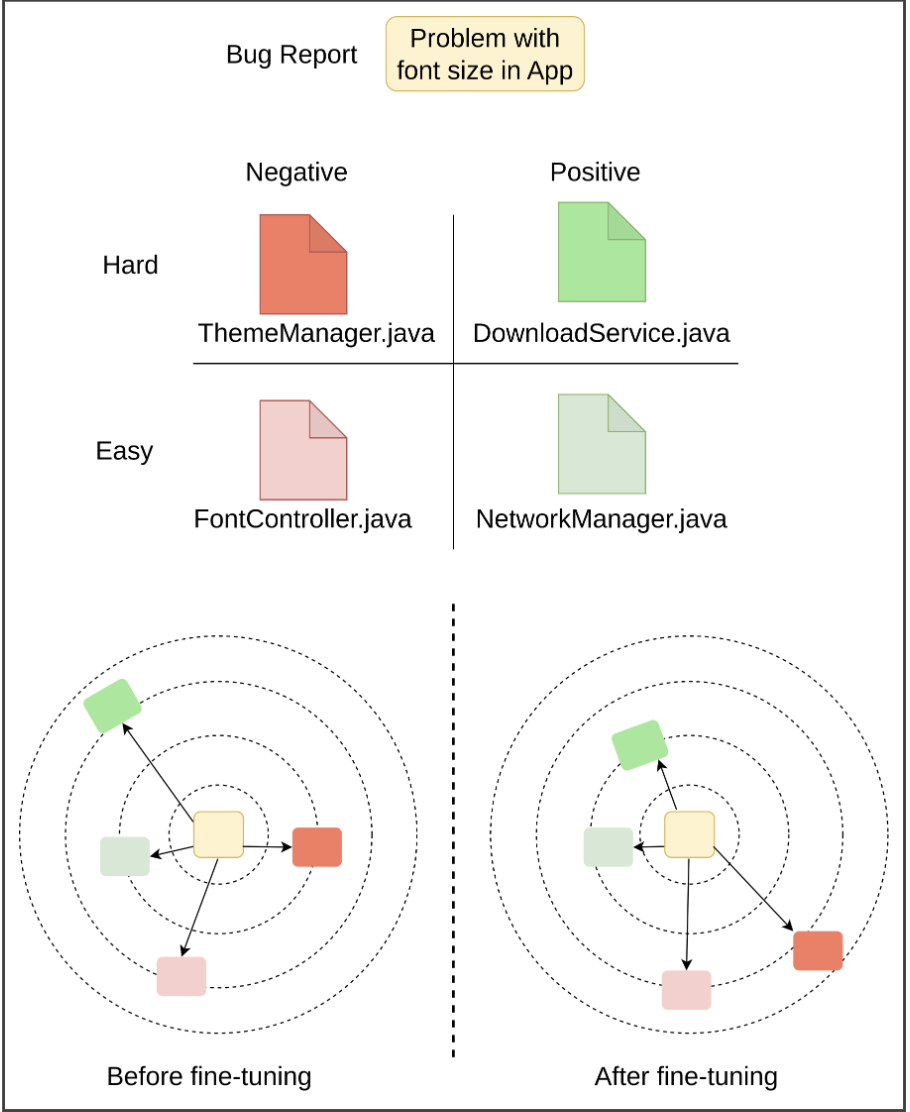
A zero-shot hybrid retrieval system combining dense and sparse signals via Reciprocal Rank Fusion. The embedding model was trained with in-batch hard negative mining. Outperforms OpenAI's third-generation embedding model by up to 38% on bug localization benchmarks — zero-shot, no task-specific fine-tuning.
IEEE Transactions on Software Engineering, 2025
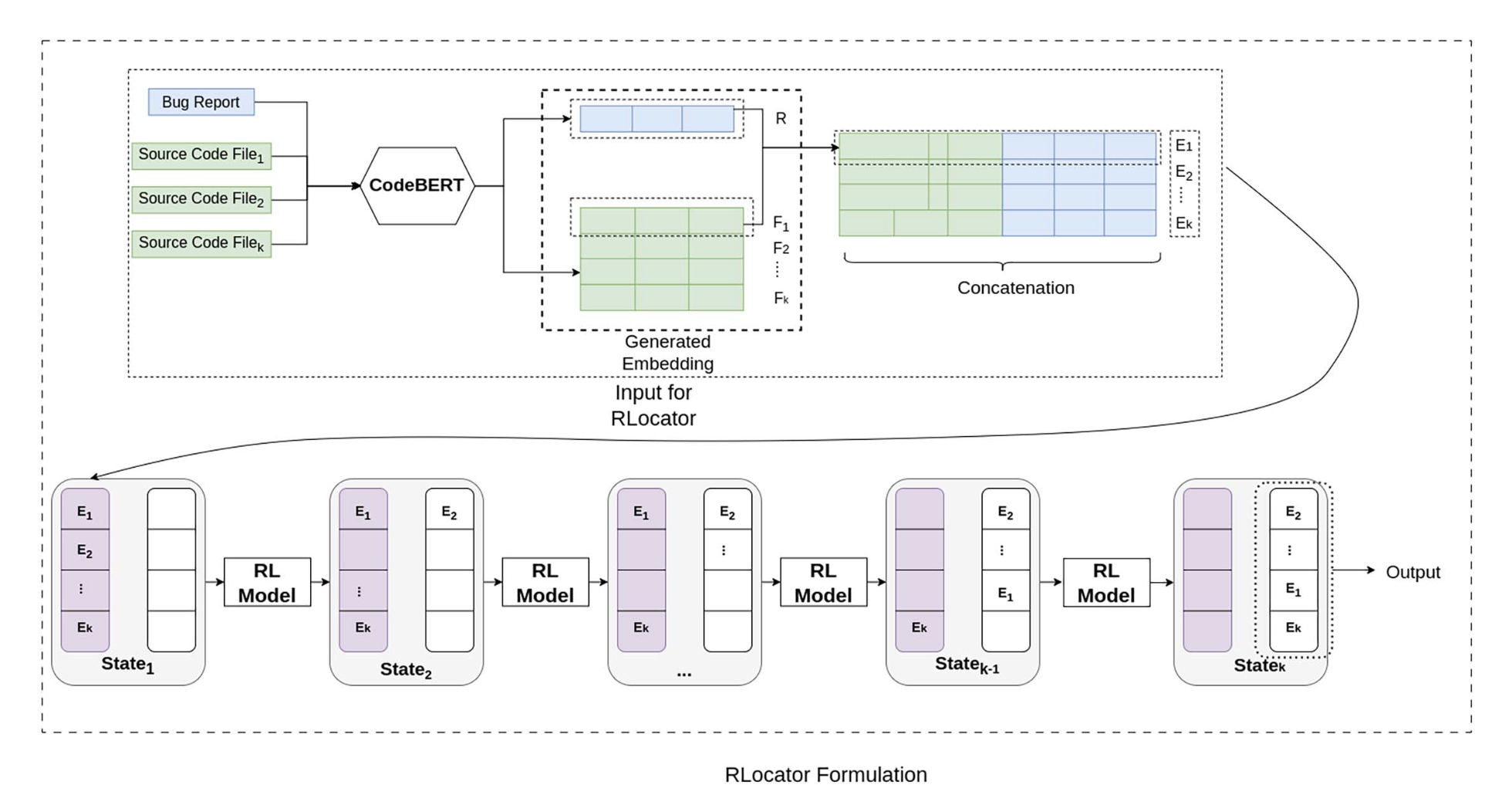
RLocator: Reinforcement Learning for Learning-to-Rank
A learning-to-rank model using actor-critic reinforcement learning to rank source code files given a bug report. Trained on developer feedback signals rather than static labels. Outperforms BM25 and neural baselines by 13% MAP.
IEEE Transactions on Software Engineering, 2024
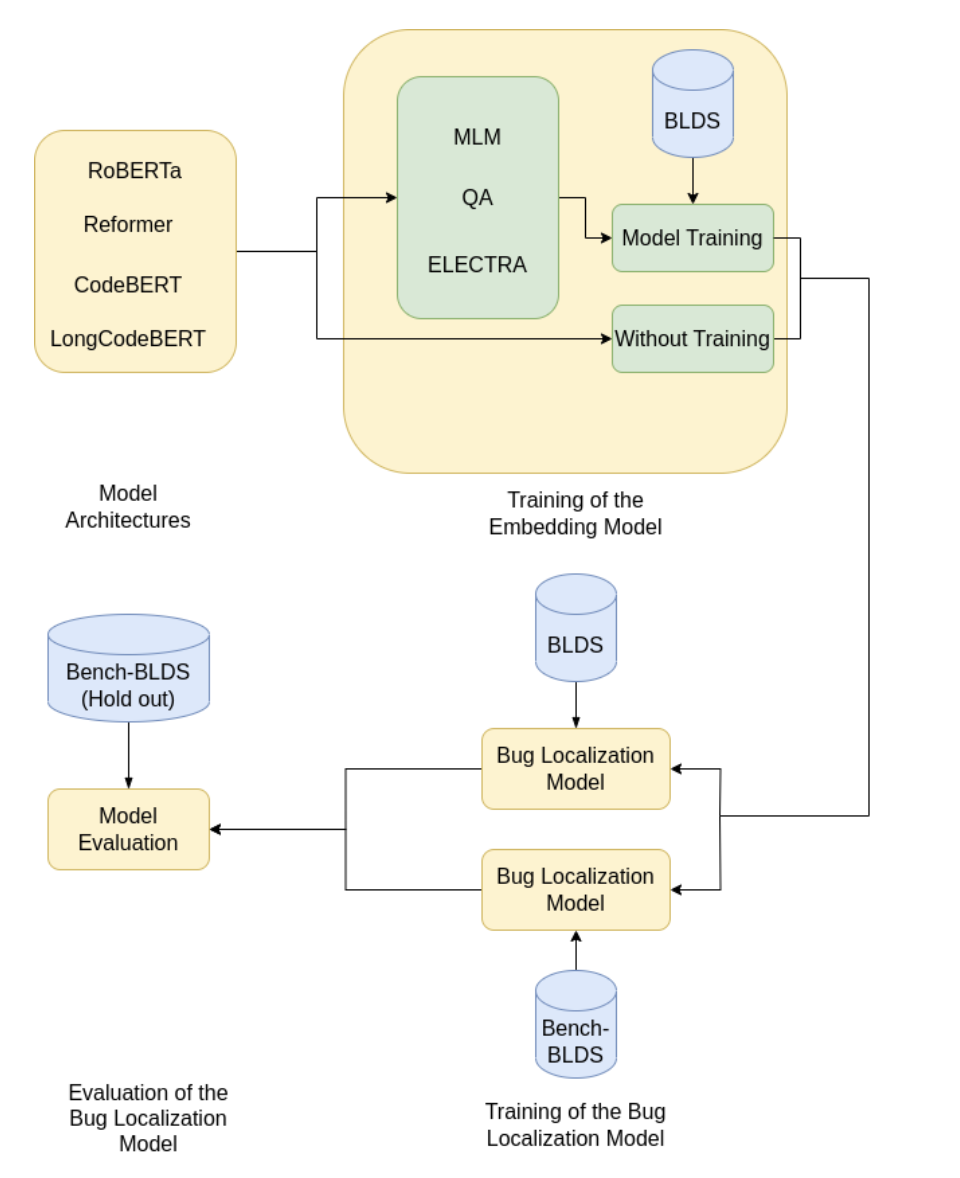
Embedding Design Choices for Code-Language Retrieval
Evaluated 32 embedding model configurations to identify what training strategies matter most for code-text retrieval. Key finding: adversarial training techniques produce more robust and generalizable models than architecture changes alone.
NLBSE Workshop, ACM/IEEE, 2024
Vulnerability Detection on Realistic Datasets
Showed that existing vulnerability detection models fail to generalize due to dataset curation bias. Proposed a new curation technique and benchmarked six models including CodeLlama and Mixtral. Models trained on the corrected dataset showed 30% improvement in generalization.
IEEE Transactions on Software Engineering, 2024
Publications
BLAZE: Cross-Language and Cross-Project Bug Localization via Dynamic Chunking and Hard Example Learning Partha Chakraborty,
IEEE Transactions on Software Engineering (TSE), 2025.
Rlocator: Reinforcement learning for bug localization Partha Chakraborty,
IEEE Transactions on Software Engineering (TSE), 2024.
Revisiting the Performance of Deep Learning-Based Vulnerability Detection on Realistic Datasets Partha Chakraborty,
IEEE Transactions on Software Engineering (TSE), 2024.
Aligning Programming Language and Natural Language: Exploring Design Choices in Multi-Modal Transformer-Based Embedding for Bug Localization Partha Chakraborty,
Third ACM/IEEE International Workshop on NL-based Software Engineering (NLBSE), 2024.
A Survey-Based Qualitative Study to Characterize Expectations of Software Developers from Five Stakeholders Partha Chakraborty,
Proceedings of the 15th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2021.
How do developers discuss and support new programming languages in technical Q&A site? An empirical study of Go, Swift, and Rust in Stack Overflow Partha Chakraborty,
Information and Software Technology (IST), 2021.
Understanding the motivations, challenges and needs of blockchain software developers: A survey Partha Chakraborty
Empirical Software Engineering (EMSE), 2019.
Empirical Analysis of the Growth and Challenges of New Programming Languages Partha Chakraborty,
IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), 2019.
Understanding the software development practices of blockchain projects: a survey Partha Chakraborty,
Proceedings of the 12th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM), 2018.
Education
University of Waterloo
Ph.D. in Computer Science January 2021 - November 2024- Specialization: Artificial Intelligence
- Advisor: Professor Meiyappan Nagappan
- Thesis Dissertation: Optimizing Automated Bug Localization for Practical Use [Dissertation]
Bangladesh University of Engineering and Technology
B.Sc. in Computer Science and Engineering Jul 2014 - Oct 2018- Major: Software Engineering
- Advisor: Rifat Shahriyar
- Thesis: An Empirical Study on the Growth of New Languages in Stack Overflow
Services
- Program Committee Member: Mining Software Repository 2025 Data and Tool Showcase Track
- Reviewer:
- IEEE Transactions on Software Engineering (TSE) - 2022, 2023, 2024
- Empirical Software Engineering (EMSE) - 2024
- ACM Transactions on Software Engineering and Methodology (TOSEM) - 2024
- Teaching:
- TA for CSE 446 - Software Design and Architecture
- TA for CSE 348 - Introduction to Database Systems
- TA for CSE 230 - Introduction to Computers and Computer Systems
- Mentored 1 UWaterloo CS undergraduate student on a research project.
Skills
- Languages: Python, Java, C++, C
- Frameworks: PyTorch, TensorFlow, Sentence Transformers, ONNX, LiteLLM, Hugging Face
- Search & Retrieval: Hybrid Search, BM25, Dense Retrieval, RRF, Learning to Rank, Bi-Encoder, Cross-Encoder, Hard Negative Mining, RAG
- Vector & Databases: Milvus, Elasticsearch, Snowflake, PostgreSQL, MySQL
- Evaluation: MAP, MRR, nDCG, Hit@K, Faithfulness, Context Relevance, Completeness
- Cloud & Infra: AWS, SageMaker, Google BigQuery, Apache Spark, Docker
- Monitoring: EvidentlyAI, Datadog, Prefect
- Tools: Git, Linux, Shell Script
Notes
Occasional writing on things I have built or figured out the hard way.